制約なし凸最適化問題に対する最急降下法と,ノルム選択,目的関数に強凸性を仮定するときの収束解析をまとめる
本記事は以下の過去記事の内容を用います.
制約なし凸最適化問題の目的関数に強凸性を仮定することの意味について考える - エンジニアを目指す浪人のブログ
降下法の枠組みと,厳密直線探索,バックトラッキング直線探索の概要をまとめる - エンジニアを目指す浪人のブログ
制約なし凸最適化問題に対する勾配降下法と目的関数に強凸性を仮定するときの収束解析をまとめる - エンジニアを目指す浪人のブログ
二次ノルムの定義をメモする - エンジニアを目指す浪人のブログ
二次ノルムの双対ノルムを導出する - エンジニアを目指す浪人のブログ
制約なし凸最適化問題に対する最急降下法(steepest descent method)について,内容をまとめておくことにしました.Boyd and Vandenberghe(2004)の9章4節をベースにしています.なお,本記事の最急降下法におけるノルムとしてユークリッドノルムを選択したものについて,最急降下法ということも多いようです.
=================================================================================
目次
0. 準備
2. ノルム選択の例
2.1. ユークリッドノルム
2.2. 二次ノルム
2.3.
ノルム
3. 考察
3.1. 収束解析
3.2. 二次ノルムと座標変換
[ 0. 準備 ]
冒頭の過去記事(制約なし凸最適化問題の目的関数)[ 0. 準備 ]と同じです.
冒頭の過去記事(降下法の枠組み)の内容も必要です.
[ 1. 最急降下法 ]
[ 1.1. 理論 ]
の
のまわりのテイラー展開の一次近似は以下です.
は通常の内積です.
(1.1.1)
テイラーの定理(文献[2])
右辺第二項 は方向
における
の
での方向微分(directional derivative)といい,小さなステップ
に対する
の近似的な変化です.方向微分
が負の値をとるときステップ
は降下方向(descent direction)です(冒頭の過去記事(降下法の枠組み)(1.1.6)にあります).
方向微分を可能な限り負にする を選択する方法について述べます.方向微分
は
に対して線形なので,(与えられる
が降下方向,すなわち
であれば)
を大きくすることで
を好きなだけ負にすることができます.問いを目的にかなったものにするためには,
のサイズを制限するか
の長さを正規化しなければなりません.
を
上の任意のノルムとします.(ノルム
の意味での)正規化された最急降下方向(normalized steepest descent direction)を定義します.(複数の最急降下方向があり得ます.)
(1.1.2)
これは以下のように解釈できます. ノルムの意味での単位球内で,方向
と同方向(方向
と反対方向)に最大限伸ばした方向を意味します.
(1.1.3)
をスケーリングすることで得られる,正規化されていない最急降下ステップ
を考慮すると便利です.
は双対ノルムです(文献[3]にあります).
(1.1.4)
(1.1.3)
は,
でないかぎり降下方向(冒頭の過去記事(降下法の枠組み)(1.1.6))であることがわかります.
(1.1.5) (1.1.4)
(1.1.3)
双対ノルムの定義(文献[3])
[ 1.2. アルゴリズム ]
最急降下法は探索方向に最急降下方向 を用います.アルゴリズムを以下に示します.厳密直線探索(exact line search)とバックトラッキング直線探索(backtracking line search)は冒頭の過去記事(降下法の枠組み)にあります.

厳密直線探索(冒頭の過去記事(降下法の枠組み)(1.2.1))を用いるときは,スケールファクターの効果はないので と
の区別はありません.
[ 2. ノルム選択の例 ]
最急降下方向を決定するときに用いるノルムによって,最急降下方向が変わります.本章では,いくつかのノルムについて,それらを選択する場合の性質を調べていきます.
[ 2.1. ユークリッドノルム ]
ノルム としてユークリッドノルム
を選択すると,双対ノルム
です(文献[3]にあります).このとき以下を得ます.この
は勾配降下法(gradient descent method)(冒頭の過去記事(制約なし凸最適化問題に対する勾配降下法)(1.1.1))に一致します.したがって,勾配降下法は最急降下法の特別な場合であることがわかります.
(2.1.1) (1.1.2)
(2.1.2)
(2.1.1)
[ 2.2. 二次ノルム ]
ノルム として二次ノルム(quadratic norm)(冒頭の過去記事(二次ノルムの定義)定義.にあります)
を選択すると,任意の
について双対ノルム
です(冒頭の過去記事(二次ノルムの双対ノルム)事実.にあります).このとき以下を得ます.
(2.2.1)
(2.2.2) (1.1.4)
(2.2.1)
二次ノルムの意味での正規化された最急降下方向 の概念を図示すると以下です.

次に,二次ノルムの意味での最急降下方向 を,座標変換を行った後の凸最適化問題に対する勾配降下法による探索方向と解釈する場合について考えます.以下の座標変換を考えます.
です.
(2.2.3)
元の座標系における点 の二次ノルムは座標変換後の座標系における点
のユークリッドノルムに一致します.
(2.2.4)
(2.2.3)
この座標変換(2.2.3)を用いる,元の凸最適化問題と等価な凸最適化問題を考えると,その問題を解くことにより,元の問題を解くことができます.そのために関数 を以下で定義します.
(2.2.5)
(2.2.3)
に勾配降下法(冒頭の過去記事(制約なし凸最適化問題に対する勾配降下法)(1.1.1))を適用するとき,点
(元の座標系における点
に対応します) における探索方向は以下です.元の凸最適化問題の探索方向も得ます.
(2.2.6)
連鎖律(文献[7])
(2.2.7) (2.2.3)
(2.2.6)
この は(2.2.2)に一致します.いいかえると,二次ノルム
の意味での最急降下法は,座標変換
を行った凸最適化問題に対する勾配降下法(を元の座標系から見たもの)として考えることができます.
[ 2.3. ノルム ]
ノルム として
ノルム(文献[4]にあります)
を選択すると,双対ノルム
です(文献[3][4]にあります).以下のような
を定義します.
はベクトルの第
要素です.
(2.3.0)
このとき以下を得ます. は標準基底です(文献[5]にあります).
(2.3.1)
(2.3.2) (1.1.4)
(2.3.0)
(2.3.1)
このように, ノルムの意味での最急降下法は常に標準基底(あるいは負の標準基底)を選択するものです.それは
の近似的な変化すなわち(1.1.1)右辺第二項
を最小化する座標軸の方向を意味します.
ノルムの意味での正規化された最急降下方向
の概念を図示すると以下です.
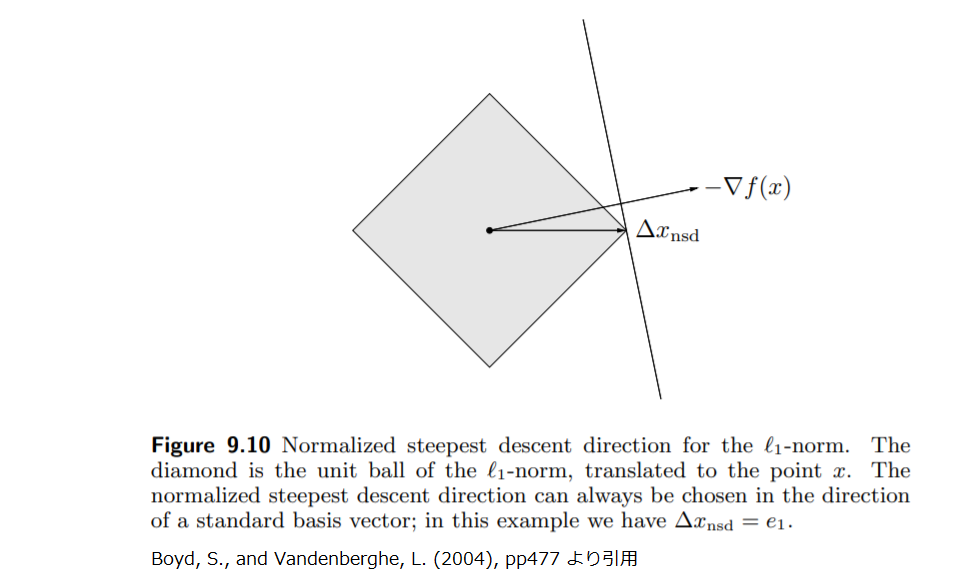
ノルムの意味での最急降下法は自然な解釈を持ちます: 各反復において
の要素の中で絶対値が最大となるものを選択し,その
の符号にしたがって
を増加あるいは減少させます.このアルゴリズムは各反復において
の一つの要素のみ更新するので,座標降下法(coordinate descent algorithm)といいます.これは厳密直線探索を非常に簡単にすることができます.
[ 3. 考察 ]
[ 3.1. 収束解析 ]
目的関数に強凸性を仮定し,最急降下法とバックトラッキング直線探索を用いるとします.この設定の下,任意のノルム の意味での収束について調べていきます.勾配降下法(冒頭の過去記事(制約なし凸最適化問題に対する勾配降下法)にあります)の収束解析の拡張になっています.
ノルムの同値性(equivalence of norms)を用います(文献[4]にあります).有限次元ノルム空間において任意のノルムは互いに同値なので, 上の任意のノルムはユークリッドノルムで抑えられます.したがって以下を得ます.
(3.1.1.a)
(3.1.1.b)
目的関数 は劣位集合(冒頭の過去記事(制約なし凸最適化問題の目的関数)(0.2.1)にあります)
上で強凸(strongly convex)であると仮定します.強凸性を仮定することにより得られる不等式である冒頭の過去記事(制約なし凸最適化問題の目的関数)(1.2.2)で,
として以下を得ます.
(3.1.2)
(1.1.5)
(3.1.1.a)
(1.1.4)
(1.1.2)
(3.1.2)(※)
(3.1.2)(※※)
冒頭の過去記事(制約なし凸最適化問題に対する勾配降下法)(2.1.3)と同様の式変形
この(3.1.2)(※)は,冒頭の過去記事(制約なし凸最適化問題に対する勾配降下法)(2.1.3)(※)の を
で,また
を
でおきかえたものです.したがって,ここから先は,冒頭の過去記事(制約なし凸最適化問題に対する勾配降下法)(2.3.1)以降の議論と同様に考えることができます.冒頭の過去記事(制約なし凸最適化問題に対する勾配降下法)(2.3.7)の
を
で,また
を
でおきかえると以下を得ます.
(3.1.3)
(3.1.1.b)
冒頭の過去記事(制約なし凸最適化問題の目的関数)(1.1.5)
以下を定義します.
(3.1.4)
したがって冒頭の過去記事(制約なし凸最適化問題に対する勾配降下法)(2.2.4)(※)あるいは同記事(2.3.9)とほぼ同じ以下を得ます.これは勾配降下法と同様に一次収束です.
(3.1.5)
[ 3.2. 二次ノルムと座標変換 ]
最急降下法のノルム選択は収束の速さに大きな影響を与えます.簡単のため,最急降下法のノルムに -二次ノルムを選択した場合について考えます.本記事[ 2.2. 二次ノルム ]で示したように,この場合の最急降下法は座標変換(2.2.3)を行った座標系における最適化問題に勾配降下法を適用した場合と等価です.冒頭の過去記事(制約なし凸最適化問題に対する勾配降下法)にあるように,勾配降下法は劣位集合(あるいは最適点の付近のヘッセ行列)の条件数が適度であれば上手くいき,大きければ上手くいきません.したがって,座標変換
を行った後の劣位集合の条件数が適度であれば最急降下法は上手くいきます.
ここまでの考察は行列 の選択の方針を与えます:
は座標変換を行った後の劣位集合の条件数が適切になるように選択すべきです.
のヘッセ行列は以下です.
(3.2.1) 連鎖律(文献[7])
たとえば最適点 における
のヘッセ行列
の近似
を既知とするとき,非常に良い
の選択は
です. このとき
のヘッセ行列は最適点
に近い範囲では単位行列
となり,したがって条件数は
です.
に近い範囲では劣位集合が点
を中心とする球で近似できることを意味します.
(3.2.2)
座標変換を用いずに同じことがいえます.座標変換 を行った後の劣位集合の条件数が小さいことは以下の楕円
が座標変換を行う前の劣位集合の形のよい近似になっていることと等価です.(いいかえると,この楕円に適切なスケーリングと平行移動を行うと座標変換を行う前の劣位集合のよい近似になっています.)(この楕円を座標変換すると球に近いです.)
(3.2.3)
まとめると,座標変換後の問題が適度な条件数となるように を選択する場合に二次ノルムの意味での最急降下法は上手くいきます.
=================================================================================
以上,制約なし凸最適化問題に対する最急降下法と,ノルム選択,目的関数に強凸性を仮定するときの収束解析をまとめました.
参考文献
[1] Boyd, S., and Vandenberghe, L. (2004), Convex Optimization, Cambridge University Press.
[2] Wikipedia Taylor's theorem のページ https://en.wikipedia.org/wiki/Taylor%27s_theorem
[3] Wikipedia Dual norm のページ https://en.wikipedia.org/wiki/Dual_norm
[4] Wikipedia Norm (mathematics) のページ https://en.wikipedia.org/wiki/Norm_(mathematics)
[5] Wikipedia Standard basis のページ https://en.wikipedia.org/wiki/Standard_basis
[6] Mathematics Stack Exchange https://math.stackexchange.com/questions/3260055/steepest-descent-for-the-quadratic-norm
[7] Stanford University Stephen Boyd先生のノート http://210.43.0.57/moocresource/data/20100601/U/stanford201001009/review7_single.pdf